Tuning no Postgres utlizando View Materializada
Fala pessoal, espero que estejam todos muito bem! Sei que faz algum tempo desde o último post, mas pretendo retomar as publicações a partir de agora. Para recomeçar com tudo, vamos falar sobre como um DBA do SQL Server conseguiu otimizar o desempenho no PostgreSQL.
O desafio era otimizar a query abaixo:

A query é relativamente simples, porém, o grande desafio está na cardinalidade. Estamos lidando com um alto volume de dados e uma modelagem N:N, o que tornou o tuning bastante desafiador.
Após a execução do plano, pude observar alguns pontos. Criamos índices para aprimorar a consulta, mas mesmo assim, nada disso resultou em um desempenho aceitável para a query.

Para a galera do SQL Server (assim como eu rs), podemos utilizar o comando: EXPLAIN (FORMAT JSON, VERBOSE, ANALYZE) no PgAdmin para visualizar o plano de execução de forma gráfica. Ufa, isso realmente facilitou minha vida.

Foi então que comecei a analisar os dados e desmembrar a query, percebendo que estavam sendo recuperadas quase 4 milhões de linhas, mas o DISTINCT resultava em apenas 2 linhas. Foi nesse momento que pensei: "E se eu conseguisse trazer apenas essas duas linhas distintas? Ou realizar um DISTINCT com menos linhas?" Foi aí que elaborei a seguinte query:

Essa query em si não é mais performática do que a original, mas avançando na ideia e relacionando-a com os estudos em PostgreSQL, pensei em utilizar uma view materializada e indexá-la, para que dessa forma a query seja muito mais eficiente. No entanto, ainda havia alguns desafios, como ajustar a query para que fosse dinâmica, ou seja, funcionasse para qualquer parâmetro. Além disso, enfrentei a particularidade da view materializada, que não atualiza os dados automaticamente. Assim, como pré-requisito, era crucial entender com que frequência poderia atualizar a view materializada.
Fui atrás do desenvolvedor para compreender onde essa query seria utilizada e foi então que descobri que precisaria atualizar a view materializada apenas uma vez por dia. Isso ocorria porque a tabela envolvida somente recebia carga uma vez por dia. Após essa carga diária, o uso da view seria 100% seguro, tornando-se um caso perfeito para a utilização da view materializada.
Superando esse obstaculo, foi para a query, e construi a seguinte query:
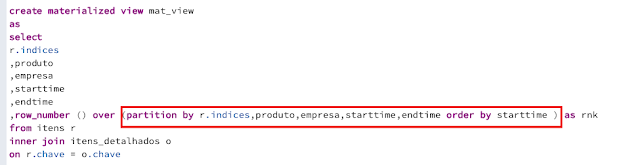
O desafio aí foi compreender que, para a window function funcionar corretamente, seria necessário incluir todos os campos no PARTITION BY. Ao fazer isso, eu poderia reduzir a quantidade de valores para os quais seria necessário aplicar um DISTINCT.
Na query original, eu precisaria aplicar um DISTINCT em quase 4 milhões de linhas. Mesmo que eu removesse o DISTINCT do banco e solicitasse que fosse feito na aplicação, poderia causar um overhead no sistema e, de qualquer forma, eu estaria transferindo 4 milhões de linhas do banco para a aplicação.

Utilizando a view materializada, incorri no custo de trazer 34 linhas e realizar o DISTINCT nessas 34 linhas. A questão é: é preferível aplicar o DISTINCT em 34 linhas ou em 4 milhões?

Query original: 43 segundos

View materializada: 230 milessegundos.

Bem pessoal por hoje é só, vou anexar os scripts no github, para que vocês possam refazer o lab e treinar!
Até a próxima!
link: https://github.com/LeleSp6/Tuning_view_materializada-no-postgres/blob/main/scripts


Comentários
Postar um comentário